Depth cameras and RGB-D SLAM
11.06.2020
今回は、Depth Cameraが、VisualSLAM手法にどのようにフィットするのか、そして、どのようにSLAMアルゴリズムのパフォーマンスを向上させることができるのかについて触れています。
(以下、英文のみ)

Over the last several articles, we have looked at different approaches to visual SLAM – direct and indirect methods. Both methods of SLAM were described assuming using either a single camera or a stereo camera. Getting the proper depth of features and objects in the field of view of the camera drives much of how well SLAM performs. I wanted to touch on how depth cameras fit into these visual SLAM methods, and how they can improve the performance of SLAM algorithms.
Depth Cameras
There are a number of different approaches to getting depth information, and we’ll take a look at three types of depth cameras. Each approach has its own advantages, and can be affected by the environment it is used in.
Stereo cameras
We discussed how stereo cameras work in a previous article. In essence, stereo cameras work by matching pixels between the images from each camera and triangulating the pixel depth using the baseline (distance between the cameras).
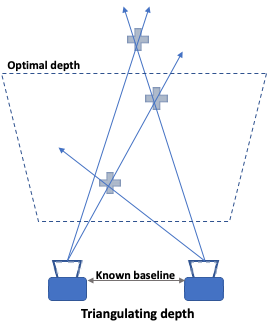
Two key advantages of stereo cameras are the cost of components, and how it performs outdoors in bright areas. On the other hand, the algorithmic cost in calculating the depth is relatively high, and low light performance can be poor. The accuracy of depth is driven by three factors: baseline distance, resolution, and lens focal length. A wider baseline and focal length provide better accuracy at range, but at the same time increases the minimum distance where depth can be determined. Rectification is also another important factor in stereo cameras and it is directly affected by the camera calibration. Using rectification, the corresponding scanlines of the left and right cameras are found and used for matching the featured pixel in the left and right images.
Active Stereo
Some systems add a projector to a single or stereo camera system. This method uses the projection to either simplify the correspondence matching between the camera images, i.e., structured-light or measure the depth directly, i.e., Time-of-Flight (ToF). As a major advantage, this type of approach performs very well in low light environments, and if used in a stereo setup, the system could fall back to the standard passive stereo depth when objects are out of the projector range or if the projection is overpowered by ambient light.
Structured Light (and Coded Light) Cameras
Structured light and coded light cameras use a conceptually similar approach in using a single camera but introducing an IR projector paired to the camera sensor. The projector emits a known pattern (typically lines or speckled dots, see below) on the scene and analyzes the distortions of these lines or dots to determine the depth.
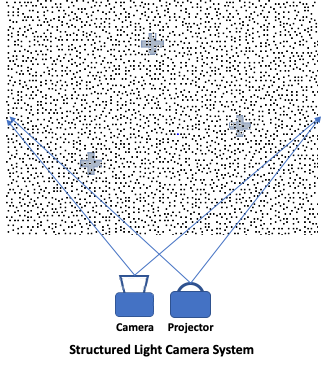

The first Microsoft Kinect (2010 – 2012) used structured light developed by PrimeSense before Apple acquired them in 2013. The Kinect brought depth sensors to the mass market (at $150, it was at least a magnitude cheaper than previously available solutions), and opened the door for a lot of research around the applications of depth sensors, including RGB-D SLAM.

Structured light sensors provided highly accurate depth data, at a relatively high-resolution, and operated well in low light environments. However, it is more expensive than a stereo camera module and requires more power to run the system (both to run the projector and compute the depth). Also, the range is limited (typically under 5 – 7m) and doesn’t work well on highly reflective surfaces, or in outdoor environments, where the sun would overpower the projector.
Time-of-Flight (ToF) Cameras
As the name implies, a ToF camera aims to measure the time which takes the light to be captured after bouncing off objects illuminated by a light source (typically LED, IR, or laser) paired with the camera. In pulsed light systems, the camera shutter is synchronized with the illuminator where the delay in returning light pulse is measured to calculate the distance to the reflection point. In contrast, continuous light systems will emit modulated amplitudes of light, and then measure the returning light to estimate the distance.
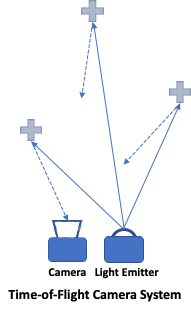
The Microsoft Kinect for Xbox One launched in 2013, replaced the structured light system with a ToF system, and we see an increasing number of mobile phones with depth capabilities using ToF sensors as well.
ToF cameras provide an optimized (however far from ideal) solution compared to passive stereo cameras and structured light cameras in that they have the lowest depth computing cost, relatively high resolution, good depth accuracy (~1cm), and ToF camera modules typically cost less than structured light systems. Similar to structured light cameras, ToF cameras are affected by reflective surfaces, may have interference from other ToF cameras, and have limited range. Environments with multiple reflective surfaces will also diminish the accuracy of depth. The range can be scaled by increasing the power of the light emitter or using lasers, but at the expense of power and cost.
Snapshot of depth camera characteristics
The table below attempts to generalize the different depth cameras characteristics based on commonly available systems we have used as part of our SLAM solution.

RGB-D SLAM
The mass-market availability of the Microsoft Kinect sensor renewed research activity in RGB-D SLAM, and techniques taking advantage of a high-resolution depth map created from it. For both direct and indirect methods of visual SLAM, the use of structured light and ToF cameras meant a gain in overall performance – both in accuracy and computational load.
If you recall from previous articles on direct and indirect SLAM, both methods require accurate depth estimates. For stereo systems, pixels between the left and right images were matched and depth derived by triangulating over the known baseline. For mono camera systems, image frames over time were used to get a baseline for points of interest. This was a computationally expensive process in the overall SLAM pipeline, and in the mono camera case, acquiring an accurate measure of the baseline over time was very difficult. The introduction of structured light and ToF cameras helped alleviate both these problems by reducing the amount of computation needed, and at the same time providing accurate depth for every pixel (within range).
However, the limitations of these cameras also limited scenarios and use cases for systems using these cameras:
– Primarily indoor operations where the source projection or lighting didn’t get overpowered by the ambient lighting
– Challenges in large open spaces that exceed the range of the projector or light emitter, where there are limited detectable surface or object within range at any given point
– Limit on highly reflective surfaces or transparent surfaces in the environment
– Different camera systems in each category have markedly different fall-offs in the accuracy of depth
So where does that leave us?
As you can see, there isn’t a single perfect solution for visual SLAM. What you end up with is a complex matrix of factors that need to be considered when choosing what type of SLAM to implement, and with what type of sensors. Some basic questions will include:
● What is the expected operating environment?
– Indoor, outdoor, open space, dynamic environment with moving objects and people, dark, etc…
– Are there a lot of features? Does lighting or the scene change over time?
– Will there be multiple devices running SLAM in the same space?
● How large is the operating environment?
– Is it a room? Multiple rooms?
– A shopping mall or conference center?
– Stadium?
● How fast are things moving?
– The device that is running SLAM
– Other objects in the environment
– People’s safety concerns?
● Is this a known area where mapping can be done prior to operation?
● What are your cost constraints?
– Can you afford a LiDAR or ToF sensor in your system?
● What are your computing constraints?
– High-end computer?
– Raspberry Pi?
● What are your memory constraints?
– 16GB?
– 1GB?
I’ll leave you with these questions for now. I will cover LiDAR SLAM in my next article, and then return to this question of how to decide on what kind of SLAM could be used in various use cases and scenarios.
For further reading:
Newcombe, et al, “KinectFusion: Real-Time Dense Surface Mapping and Tracking,” (PDF)


