SLAMには多くの形式や手法がありますが、まずは機能ベースのvisual SLAMから始めましょう。Direct Visual SLAMや、深度センサ付きカメラを使用するSLAM、LiDARなどの他のSLAM手法については、以降の記事で説明します。
まずは、Visual SLAMについて、概説します。(以下、英文のみ)

In my last article, we looked at SLAM from a 16km (50,000 feet) perspective, so let’s look at it from 2m. Not close enough to get your hands dirty, but enough to get a good look over someone’s shoulders. SLAM can take on many forms and approaches, but for our purpose, let’s start with feature-based visual SLAM. I will cover other SLAM approaches such as direct visual SLAM, and those that use cameras with depth sensors, and LiDAR in subsequent articles.
As the name implies, visual SLAM utilizes camera(s) as the primary source of sensor input to sense the surrounding environment. This can be done either with a single camera, multiple cameras, and with or without an inertial measurement unit (IMU) that measure translational and rotational movements.
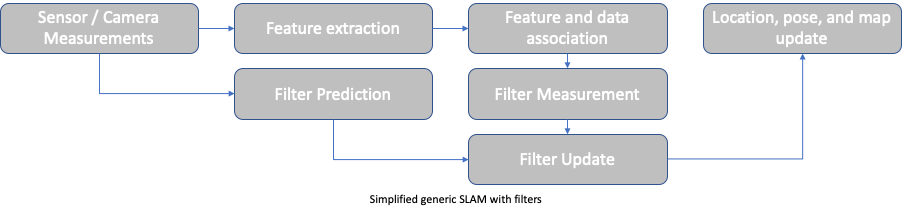
Let’s walk through the process chart and see what happens at each stage.

Sensor/Camera Measurements: Setup
In order to make this a bit more concrete, let’s imagine a pair of augmented reality glasses. For simplicity, the glasses have two cameras mounted at the temple and an IMU centered between the cameras. The two cameras provide the stereo vision to make depth estimations easier, and the IMU will help provide better movement estimations.

There are a couple specifications for the camera that help with SLAM: global shutter and grayscale sensor. Also, the tracking cameras don’t have to be super high-resolution, and typically a VGA (640x480 pixel) camera is sufficient (more pixels, more processing). Let’s also assume there is a 6-axis IMU: motion on the x, y and z-axis, and pitch, yaw and roll. Finally, these sensors should be synchronized against a common clock to match the sensor outputs against each other.
Let's start solving the puzzle
I find the process of completing a jigsaw puzzle as a good analogy for some major components of the SLAM process. The processes described below are mostly conceptual and simplified to help in understanding the overall mechanisms involved.
When the system is initialized, and the cameras are turned on, you are given your first piece of the puzzle. You don’t know how many pieces there are, and you don’t know what part of the puzzle you are looking at. You have your first stereo images and IMU readings.
Feature Extraction: Distortion correction
Most camera lenses will introduce some level of distortion to the captured images. There will be distortion from the design of the lenses, as well as distortion in each lens from minute differences during manufacturing. We can “undistort” the image through a distortion grid that transforms the image close to its original representation.

Feature Extraction: Feature points
Features in computer vision can take on a number of forms, and don’t necessarily correspond to what humans think of as features. Features typically take the form of corners, or blobs, a collection of pixels that uniquely stand out, and should be able to be consistently identified from an image, and occasionally edges. The figure below depicts the features detected (left), how they would be represented in a map (right).

Feature Extraction: Feature matching and depth estimation

Given these stereo images, we should be able to see overlapping features between the images. These identical features can then be used to estimate the distance from the sensor. We know the orientation of the cameras and the distance between them. We use this information to perform image rectification - the mapping pixels between the two images against a common plane. This is then used to determine the disparity of the common features between the two images. Disparity and distance are inversely related, such that as the distance from the camera increases, the disparity decreases.
Now, we can estimate the depth of each of the features using triangulation.
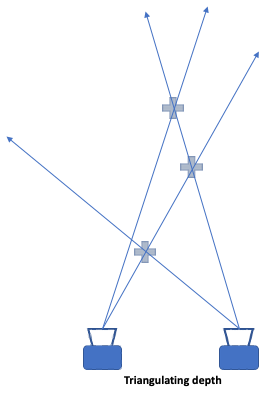
In a single camera scenario, we cannot infer depth from a single image, but as the camera moves around, depth can be inferred through parallax by comparing the features in subsequent images.
Data association
The data association step takes the features detected, along with its estimated location in space, and builds a map of these features with regards to the cameras. As this process continues through subsequent frames, the system continually takes new measurements, and associates features to known elements of the map, and prunes uncertain features.
As we track the motion of the camera, we can start making predictions based on the known features, and how they should change based on the motion.
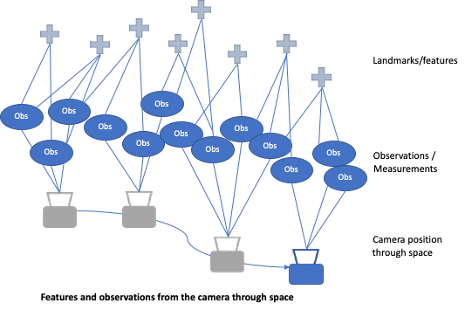
The constraint of computing resources and time (especially real-time requirements) creates a forcing function for SLAM, where the process becomes a tradeoff between map accuracy, and processing resource and time. As the measurements of features, and location/pose increase over time, representation of the observed environment has to be constrained and optimized. We’ll take a look at some of these tools, and different approaches to optimizing the model.
Location, Pose and Map Update: Kalman filters
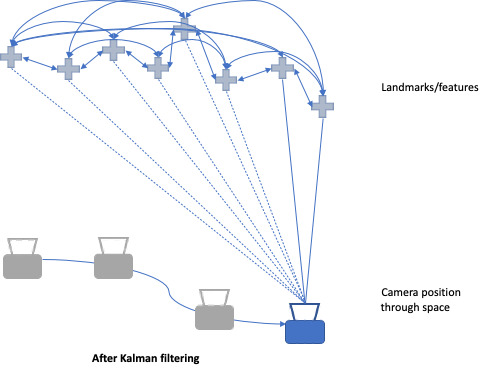
As the camera moves through space, there is increasing noise and uncertainty between the images the camera captures and its associated motion. Kalman filters reduce the effects of noise and uncertainty among different measurements to model a linear system more accurately by continually making predictions, updating and refining the model against the observed measurements. For SLAM systems, we typically use extended Kalman filters (EKF), which takes nonlinear systems, and linearizes the predictions and measurements around their mean.
Utilizing a probabilistic approach, Kalman filters take into account all the previous measurements and associate the features to the latest camera pose through the use of a state vector and a covariance matrix for each feature against one another. However, all noise and states are assumed to be Gaussian. As you can imagine as the tracked points grow, the computation becomes quite expensive, and harder to scale.
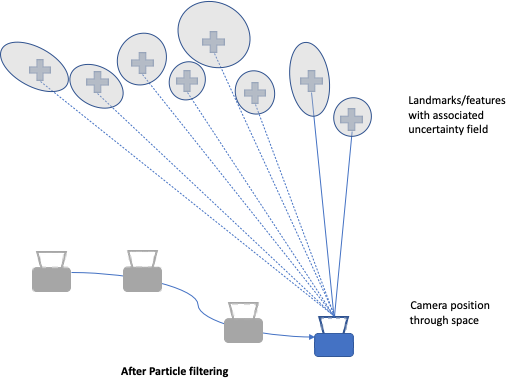
Location, Pose and Map Update: Particle filters
In contrast to Kalman filters, particle filters treat each feature point as a particle in space with some level of positional uncertainty. At each measurement this uncertainty is updated (normalized and re-weighted) against the predicted position with regard to the camera movement. Unlike Kalman filters, particle filters can handle noise from any distribution, and states can have a multi-modal distribution.
Location, Pose and Map Update: Bundle adjustment
As the number of points being tracked in space along with corresponding camera poses increase, bundle adjustment is an optimization step that performs a nonlinear least squares operation on the current model. Imagine a “bundle” of light rays from all the features connected to each of the camera observations, and “adjusted” to optimize these connections directly to the sensor position and orientation as in the figure below.
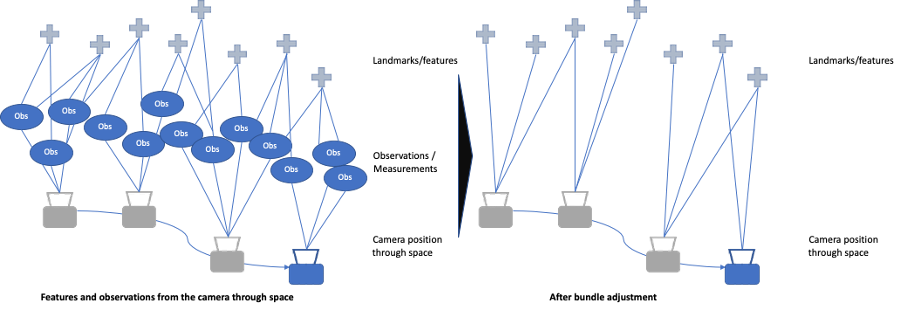
Bundle adjustment is a batch operation, and not performed on every captured frame.
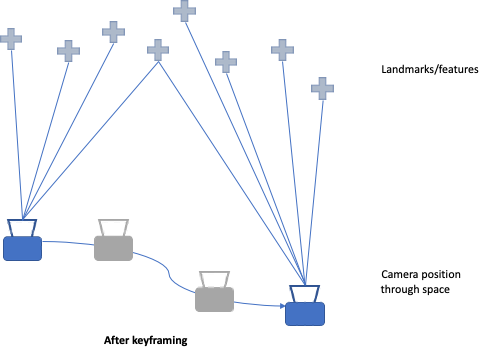
Location, Pose and Map Update: Keyframe
Keyframes are select observations by the camera that capture a “good” representation of the environment. Some approaches will perform a bundle adjustment after every keyframe. Filtering becomes extremely computationally expensive as the map model grows, however keyframes enable more feature points or larger maps, with a balanced tradeoff between accuracy and efficiency.
Post-update
Once the update step completes, the 3D map of the current environment is updated, and the position and orientation of the sensor within this map is known. There are two important concepts that loosely fit into this final step - a test to see if the system has been here before, and what happens when the system loses tracking or gets lost.
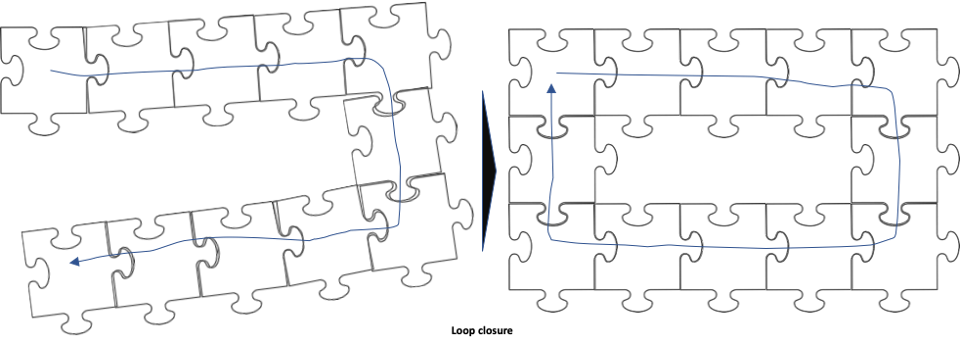
Post update: Loop closure
As the system continues to move through space and build a model of its environment, the system will continue to accumulate measurement errors and sensor drift, which will be reflected in the map being generated. Loop closure occurs when the system recognizes that it is revisiting a previously mapped area, and connects previously unconnected parts of the map into a loop, correcting the accumulated errors in the map.
Post update: Relocalization
The term localization in SLAM is the awareness of the system’s orientation and position within the given environment and space. Relocalization occurs when a system loses tracking (or initialized in a new environment), and needs to assess its location based on currently observable features. If the system is able to match the features it observes against the available map, it will localize itself to the corresponding pose in the map, and continue the SLAM process.
Final words
With the goal of trying not to be too mathy and technical, and yet conceptually descriptive enough to help get a depth of understanding of the processes that take place within one type of SLAM system, this goes a bit beyond my “5 minute read” target, but I think it’s essential to cover these fundamental concepts for visual SLAM to help with future topics.
Let me know your thoughts, comments and questions.
